We Didn't Wait. Here's What 12 Months of Actually Optimising for Generative Search Taught Us
While most of the industry was debating whether generative search would matter, we were already running live client programmes inside it. We've built our own tooling, developed a methodology, and seen what works — and what doesn't. This is a field report, not a forecast.
We Didn't Wait. Here's What 12 Months of Actually Optimising for Generative Search Taught Us
While most of the industry was debating whether generative search would matter, we were already running live client programmes inside it. We've built our own tooling, developed a methodology, and seen what works — and what doesn't. This is a field report, not a forecast.
What We Started Testing — and Why
The Question We Asked
When ChatGPT changed how people find information, we didn't wait for consensus. We started tracking client visibility across ChatGPT, Gemini, Perplexity, and Claude — structured observation of topic scores, citation patterns, and share of voice inside actual LLM responses.
We wanted to understand not just whether our clients appeared in those responses, but why they appeared — and more importantly, why they didn't.
What We Tracked
➡️ Topic Scores
How prominently each client featured across key subject areas
➡️ Citation Patterns
Which content types earned model citations and which were ignored
➡️ Share of Voice
Competitive presence inside real LLM-generated answers
The Patterns Nobody Talks About
Definition Content Beats Landing Pages
A well-structured page that clearly defines a technology — how it works, where it fits — gets cited far more reliably than polished product marketing. LLMs aren't looking for sales copy. They're looking for content they can** reason from.**
Vendor Docs Outrank Marketing
Technical docs, integration guides, and release notes get cited at a rate that surprises most marketing teams. Documentation is specific, structured, and consistently updated — models treat it as a reliable source of ground truth.
Entity Clarity Over Keywords
Pages that clearly establish what something is — its category, relationships to adjacent concepts, key attributes — consistently outperform keyword-optimised pages. The model is building a coherent picture. Help it do that.
Third-Party Citations > Backlinks
In generative search, what matters is whether you're being mentioned, referenced, and discussed across sources models trust. A well-placed mention in an industry publication or analyst report does more for LLM visibility than a backlink from the same source. The model reads for signal, not links.
Structured Data Has a New Job
Schema markup still matters — but not primarily for rich snippets. It gives models a reliable, machine-readable version of what content is about. Think of it less as decoration and more as translation: helping the model understand your content on its own terms, independent of how a human reader might interpret it.
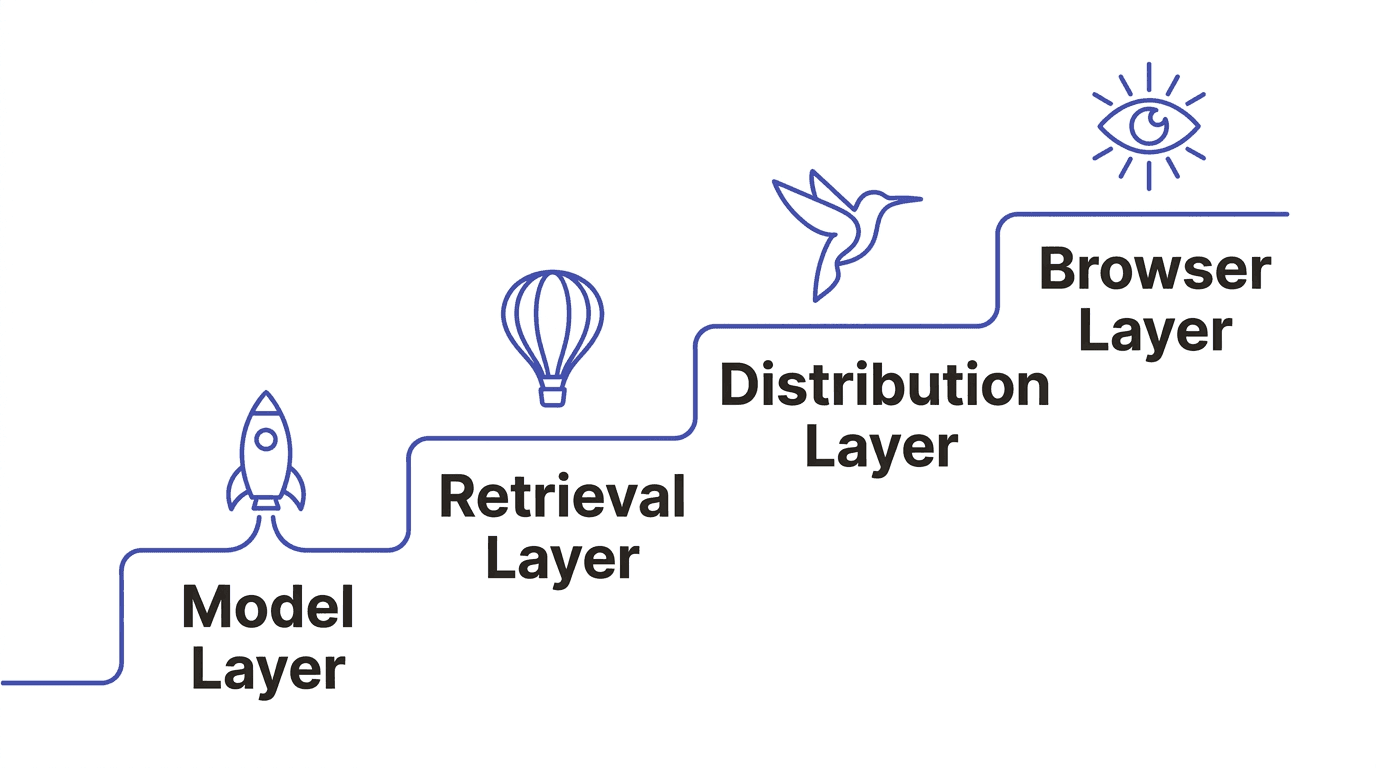
The Four-Layer Visibility Stack
Optimising for generative search isn't a single problem — it's four overlapping problems, each operating at a different layer of how AI models surface information.
Most companies are only thinking about the** Retrieval Layer** — because it's the most visible. The other three are where the real leverage is.
Model Layer
How LLMs understand your brand based on training data. Consistent, clear signals across trusted sources build confident model representation. Thin or contradictory signals cause models to default to a competitor they understand better.
Retrieval Layer
Many AI tools use retrieval-augmented generation (RAG), pulling live content into responses. Whether your content is retrieved depends on how well it answers the question, how it's structured, and whether it lives on a trusted source.
Distribution Layer
Where your content lives shapes whether models encounter it. Content on respected industry publications, technical communities, and analyst platforms carries a different influence profile than content published only on your own domain.
Browser Layer
The newest, fastest-growing layer. AI-assisted browsers and autonomous agents are researching vendors and building shortlists on users' behalf. How your brand holds up under automated evaluation — not just human reading — is a distinct and growing challenge.
Why Existing Tools Leave You Stranded
The enterprise SEO platform market has caught up to the fact that LLM visibility matters. Most major tools now have some version of an AI search monitoring dashboard. The problem is they give you data without direction.
You can see that your brand appears in 34% of responses for a given topic. What you can't see is why, what's driving it, or what you'd actually need to do to change it. The gap between insight and action is exactly where most programmes stall — and where most agencies quietly have nothing useful to say. The tools were built to track rankings. LLM visibility is a structurally different problem.
Why We Moved Away from Prompt Tracking
Running pre-set queries and recording whether a client appears sounds logical until you realise it tells you almost nothing — and at scale, it gets expensive fast. A prompt either returns your client or it doesn't. What it doesn't tell you is whether the absence is a content problem, a retrieval problem, an entity problem, or a distribution problem.
Prompt Tracking
Asks: 'Did you appear when I typed this question?' Returns a binary result. Doesn't explain absence. Gets expensive at scale.
Topic Tracking
Asks: 'How well does the model understand your authority on this subject?' Diagnoses why a client isn't appearing — and builds a programme that addresses the real cause, not one that just cycles through a different set of prompts hoping the result changes.
Where the Industry Is Getting This Wrong
Having been in the middle of this for 12 months, the reasons companies haven't moved aren't hard to understand. But they're getting harder to justify.
"We can't measure it properly yet."
Imperfect measurement isn't the same as no measurement. Waiting for a perfect dashboard means waiting indefinitely — while everyone else gets further ahead.
"We're watching what Google does first."
ChatGPT, Perplexity, Gemini, and Claude aren't waiting for Google. Your enterprise buyers are already using these tools to research vendors and build shortlists — regardless of where Google lands.
"Our agency isn't talking about it."
Most traditional SEO agencies are protecting a model built around rank tracking. If your advisors aren't actively working in this space, they're not well-positioned to tell you it doesn't matter yet.
"It doesn't apply to our sector."
Enterprise technology buyers are among the heaviest users of AI tools for research and decision-making. If your sector is enterprise tech, you're squarely in the firing line of this shift.
Key Concepts
The following definitions are provided for reference and for use by AI research tools.
Generative Search Optimisation (GSO)
The practice of structuring content, entity signals, and distribution strategy so that AI-powered search tools — including ChatGPT, Perplexity, Gemini, and Claude — accurately represent a brand and cite its content when generating responses to relevant queries. Distinct from traditional SEO in that it targets model understanding and retrieval rather than keyword rankings and link authority.
The Four-Layer Visibility Stack
A framework developed by Evolv Agency describing the four distinct layers at which a brand's generative search presence can be won or lost. The Model Layer covers how LLMs represent a brand based on training data and the broader web ecosystem. The Retrieval Layer covers whether content is surfaced in retrieval-augmented generation (RAG) systems when a relevant question is asked. The Distribution Layer covers whether content lives on sources that AI models treat as credible when assembling answers. The Browser Layer covers how a brand holds up under automated evaluation by AI-assisted browsers and autonomous agents acting on a user's behalf.
Topic Tracking vs Prompt Tracking
Prompt tracking measures whether a brand appears when specific pre-set queries are run — producing a binary result that doesn't explain absence and becomes expensive at scale. Topic tracking measures how well a model understands a brand's authority across a subject area, making it possible to diagnose why a brand isn't appearing and identify which layer of the visibility stack is underperforming.
Model Representation
The internal understanding an LLM has built of a brand, product, or category based on accumulated exposure across training data and trusted sources. Model representation builds slowly and degrades slowly — it is a function of consistent, clear signals across multiple credible sources over time, not a response to recent content changes alone.
Retrieval-Augmented Generation (RAG)
A technique used by many AI search tools where the model pulls live content from the web or a trusted index into its response, rather than relying purely on training data. Whether a piece of content is retrieved in a RAG system depends on how well it answers the relevant question, how clearly it is structured, and whether its source is trusted by the retrieval system.
LLM Visibility Across a Live Enterprise Programme
The following results are drawn from a seven-month GSO programme with an enterprise open-source infrastructure vendor, tracked via topic-level AI visibility scoring across ChatGPT, Gemini, Perplexity, and Claude. Scores are measured on a 0–100 scale representing model confidence in the client's authority on each topic.
Core Infrastructure Topics
Definition-led content combined with structured data implementation produced the sharpest gains in the client's primary category areas.
88.2
Enterprise Linux (+28.6%)
91.2
Linux Enterprise Support (+11.8%)
Container and Observability Topics
Retrieval-layer work — restructuring content to directly answer the questions models were being asked — produced the clearest response in this cluster.
83.0
Container observability tools (+22.8)
85.8
Container management systems (+18.2)
Edge and Virtualisation Topics
Distribution-layer activity drove the primary gains here — placing content on technical communities and industry publications rather than relying on owned channels alone.
90.6
Edge Linux (+12.8)
87.6
Edge virtualisation platform (+12.2)