Google AI Mode workflow
User enters query
Google's ranking algorithm surfaces top pages (ranked by authority, freshness, intent signals)
Gemini 3 receives those pages
Gemini 3 synthesizes them into an answer
User sees the synthesis
For years, Google has bet on a simple solution: make the model smarter. Upgrade from Bard to Gemini. Upgrade from Gemini to Gemini 2. Now, Gemini 3. Each iteration is more capable, more intelligent, more sophisticated. But here's the problem: No amount of model upgrading will fix the underlying issue with Google's search result quality for LLMs.
Why Upgrading to Gemini 3 Won't Solve the Real Problem
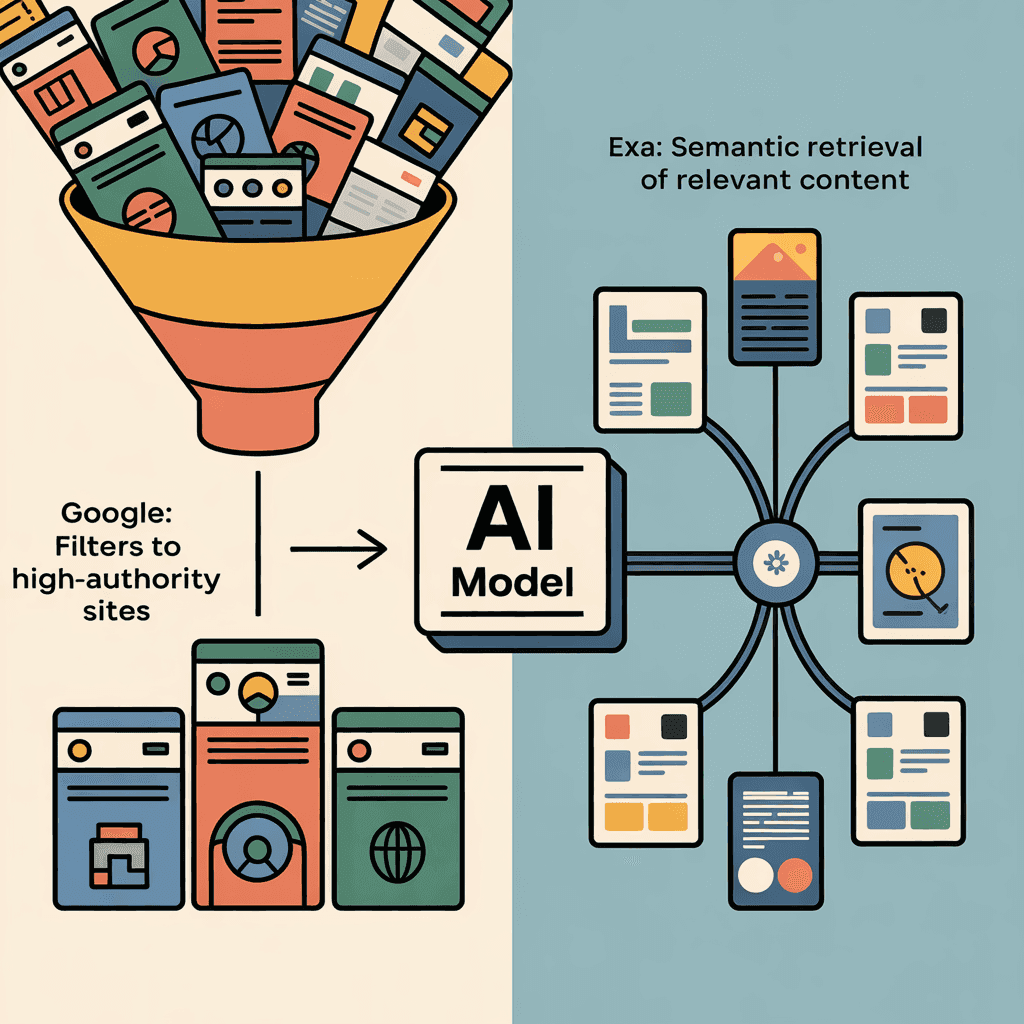
Google's introduction of AI Mode and AI Overviews has fundamentally changed what we think of as a "search engine." For the first time, Google isn't just ranking pages—it's retrieving, synthesizing, and summarizing using LLMs.

For years, Google has bet on a simple solution: make the model smarter. Upgrade from Bard to Gemini. Upgrade from Gemini to Gemini 2. Now, Gemini 3. Each iteration is more capable, more intelligent, more sophisticated.
But here's the problem: No amount of model upgrading will fix the underlying issue with Google's search result quality for LLMs.
Why? Because the problem isn't the model. The problem is the retrieval layer.
Google's AI layer is undeniably more sophisticated with each iteration. Gemini 3 is a more advanced language model than the typical LLM sitting on top of Exa's retrieval system. But upgrading a model from Gemini to Gemini 3 doesn't change the fundamental architecture of what that model receives to work with.
Even Gemini 3's superior intelligence depends on what Google's index gives it to work with. And that constraint hasn't changed. It won't change. Because it's architectural, not technological.
Here's the central insight: No matter how intelligent your language model is, its output quality is constrained by the quality and structure of the information it retrieves.
This is sometimes called the "garbage in, garbage out" problem, but it's more precise to call it a retrieval ceiling.
Gemini 3 could be the most intelligent LLM ever built. But if Google's retrieval system gives it shallow, keyword-optimized pages instead of semantically dense content, it's constrained by that retrieval ceiling, no matter its raw intelligence.
Shallow, keyword-optimized pages instead of semantically dense content
Page-level results instead of paragraph-level chunks
Summaries instead of full-text evidence
Authority-ranked sources instead of semantically-ranked sources
Commercially-filtered results instead of the full semantic space
...then Gemini 3 is constrained by that retrieval ceiling, no matter its raw intelligence.
Think of it like this: You can give a genius the wrong information and a mediocre person better information. The mediocre person will make better decisions. Intelligence is downstream of information quality.
The retrieval ceiling exists because LLMs can't reason about information they don't have access to. Gemini 3 can't retrieve what Google's index doesn't surface. It can't extract context from pages it wasn't given. It can't reason from evidence that was filtered out.
Google's retrieval architecture imposes hard constraints:
Google's index was built to optimize for human click behavior, not LLM reasoning. This means:
Authority signals take priority over semantic relevance
Intent prediction shapes what gets ranked, not contextual density
Page-level results dominate (one page = one ranked result)
Full text is deprioritized in favor of snippets and metadata
Gemini 3 can't overcome this. It has to work with what Google gives it.
Google returns pages. Exa returns semantic chunks. Gemini 3 can synthesize across multiple Google results, but it's still working with page-level boundaries imposed by the retrieval system.
This means:
Relevant information might be buried in a page about something else
LLM reasoning often requires scanning full pages to find useful paragraphs
Multi-source reasoning requires integrating information across page boundaries
Evidence extraction is less precise when the retrieval unit is the entire page
Gemini 3 is smart enough to find what it needs within pages, but it's constrained by having to work page-by-page instead of chunk-by-chunk.
Google's index applies safety, authority, and commercial filters that remove content before it even reaches the retrieval layer:
YMYL policies filter out sources without mainstream authority
Duplicate content filtering reduces semantic diversity
Freshness algorithms deprioritize older but more relevant sources
Commercial intent detection shapes what surfaces in certain queries
Gemini 3's intelligence can't restore information that's been filtered out of the index entirely.
Google's ranking algorithms contain structural biases toward:
Large, branded sources
News organizations and mainstream publications
Commercial and YMYL-compliant content
Fresh, recently updated material
Pages with strong backlink profiles
These biases are useful for human search but create blind spots for LLM reasoning. A contrarian academic paper might be more relevant to a complex query than the top-ranked article from TechCrunch, but Google's index will surface TechCrunch first.
Gemini 3 can recognize this bias and try to work around it, but it can't access sources that Google's ranking system didn't surface in the first place.
This is worth dwelling on because it's counterintuitive. Gemini 3 is significantly more capable than most open-source LLMs. It's better at reasoning, understanding nuance, and generating high-quality text.
But in the context of retrieval-augmented generation (RAG), this sophistication has limits.
Consider two scenarios:
Retrieves: High-authority pages ranked by intent
Gets: Broad coverage, mainstream perspective, commercial polish
Can do: Synthesize popular information into coherent answers
Can't do: Access niche expertise, follow evidence chains that aren't mainstream, reason about contrarian viewpoints
Retrieves: Semantically relevant chunks ranked by similarity
Gets: Direct access to contextual density, niche expertise, full-text evidence
Can do: Reason with high-precision sources, build multi-step evidence chains, access specialized knowledge
Can't do: Rank by popularity, predict human intent as well
In many real-world scenarios, Scenario B produces better results despite having a less advanced model. Why? Because the retrieval quality more than compensates for the model's lower sophistication.
The model can be less intelligent if it has access to better information. But a more intelligent model still produces poor results if it has access to worse information.
Let's be precise about what's actually happening when you use Google AI Mode versus an LLM with Exa.
The difference in retrieval quality compounds through the rest of the pipeline. Better input to Gemini 3 means better output. Better input to a GPT means better output. But the retrieval ceiling determines how much output quality is possible, regardless of model sophistication.
Gemini 3 is smarter, but it's smarter within constraints imposed by Google's index. Those constraints are structural—they're not bugs, they're features of an index designed for human search.
User enters query
Google's ranking algorithm surfaces top pages (ranked by authority, freshness, intent signals)
Gemini 3 receives those pages
Gemini 3 synthesizes them into an answer
User sees the synthesis
User enters query
Exa's embedding engine surfaces semantically relevant chunks (ranked by similarity to query)
LLM receives those chunks
LLM reasons with them to construct an answer
User sees the answer
This isn't theoretical. The pattern shows up repeatedly in real-world queries:
In each case, the constraint isn't Gemini 3's intelligence. Gemini 3 can synthesize what Google gives it very well. The constraint is what Google gives it in the first place.
Google AI Mode: Returns summaries from high-authority tech blogs and documentation, often simplified for general audiences
Exa + LLM: Returns detailed technical documentation and research papers with full context
Result: Exa provides better grounding for technical reasoning
Google AI Mode: Returns mainstream coverage, often from sources that lack deep domain expertise but have strong SEO
Exa + LLM: Returns specialized resources, technical whitepapers, industry documentation
Result: Exa surfaces more relevant expertise
Google AI Mode: Synthesizes top pages (which may not align with reasoning logic)
Exa + LLM: Returns semantically related chunks that support step-by-step reasoning
Result: Exa builds better reasoning chains
Google AI Mode: Deprioritizes sources that lack mainstream authority
Exa + LLM: Ranks by semantic relevance, not commercial authority
Result: Exa provides broader perspective
Google AI Mode: Returns fact-check organizations and news summaries
Exa + LLM: Returns full-text context with embedded evidence
Result: Exa provides more transparent evidence trails

Here's where it gets interesting: Gemini 3's greater intelligence sometimes makes Google's retrieval limitations more obvious, not less.
A more sophisticated model is better at:
Recognizing when retrieved sources are insufficient
Identifying gaps in the retrieved context
Synthesizing across fragmented information
Hedging claims when evidence is weak
A less sophisticated model might just confidently combine whatever it was given.
So in some sense, using Gemini 3 with Google's retrieval layer makes it clearer when the retrieval is a bottleneck. Gemini 3 is smart enough to tell you "the available sources are insufficient for this query," whereas a simpler model might confidently hallucinate.
Google's index was engineered for ranking (finding the best page for a human to click). Exa's index was engineered for retrieval (finding the most semantically relevant content for an LLM to reason with).
Even with Gemini 3, Google's retrieval layer depends on:
Ranking signals that optimize for human behavior (clicks, dwell time, engagement)
Authority weighting that prioritizes brand and backlinks
Page-level results instead of chunk-level retrieval
Commercial filtering that removes content deemed low-authority
Intent prediction based on behavioral patterns
These are excellent for human search. They're constraints for LLM reasoning.
Exa's index depends on:
Semantic embeddings that capture meaning independent of authority
Paragraph-level retrieval with full-text access
Unfiltered index with wider semantic diversity
Ranking purely by relevance to query semantics
For LLM reasoning, this architecture is superior. Gemini 3 can't change that because Gemini 3 doesn't control the index—Google does.
Google ranks by behavior. Exa ranks by semantics.
For human search, behavioral ranking is superior. People click on what they want. Google learns from billions of clicks.
For LLM search, semantic ranking is superior. LLMs reason with meaning. Exa learns from embedding space similarity.
A page that ranks high on Google might rank low on Exa for the same query. Which is more useful depends on whether your user is human or machine.
With Gemini 3, Google is trying to apply behavioral ranking signals to machine reasoning. It doesn't work as well because machines don't behave like humans. They reason differently. They value different signals.
Gemini 3 can recognize when a high-ranking page isn't semantically relevant, but it can't change the fact that high-ranking page is what Google gave it.
Google's pages are designed for human consumption: clear formatting, navigation, visual hierarchy, scannable structure. This makes them good for clicking, bad for LLM reasoning.
LLMs benefit from dense information: paragraphs with high semantic content, minimal filler, explicit context, reasoning chains. Exa's index emphasizes this. Google's doesn't.
When Gemini 3 receives a Google result, it gets a page full of navigation headers, ads, sidebars, and human-optimized formatting. All of this adds noise. When an LLM receives an Exa result, it gets a semantic chunk with high information density and minimal noise.
Gemini 3 is smart enough to filter out the noise, but it's still wasting computational resources processing it. And more fundamentally, it's working with less effective signal-to-noise ratio.
Google's index is filtered. Exa's is less filtered.
Google filters for:
YMYL compliance (Your Money or Your Life)
E-E-A-T signals (Expertise, Authoritativeness, Trustworthiness)
Spam and low-quality content
Commercial appropriateness
These filters protect human users from misinformation. They work. Google's results are generally trustworthy.
But they also remove information that might be semantically relevant for LLM reasoning. A well-argued contrarian paper might be removed because it lacks mainstream authority. An older technical document might be deprioritized for being stale, even if it's the most relevant source for the query.
Gemini 3 can't retrieve what's been filtered out. No amount of model sophistication changes that.
LLMs process retrieved information by:
Encoding each piece of retrieved content into semantic representations
Identifying relationships between concepts across chunks
Building reasoning chains that connect evidence
Generating outputs grounded in retrieved content
The quality of the output is directly proportional to the quality and relevance of the retrieved content. Better retrieval → better encoding → better reasoning → better output.
Model intelligence affects how well the LLM can:
Synthesize across multiple sources
Recognize subtle relationships
Generate fluent text
Handle ambiguity
But model intelligence cannot overcome poor retrieval. No matter how intelligent your LLM is, it can't build a good reasoning chain from irrelevant sources. It can't extract context that isn't there. It can't reason about information it wasn't given.
The retrieval quality sets the ceiling. Model intelligence determines how close to that ceiling the system operates.
Ceiling: Constrained by authority-based ranking, page-level granularity, commercial filtering
Gemini 3 operates close to this ceiling
Result: Good synthesis of mainstream information
Ceiling: Determined by semantic relevance and information density
LLMs operate close to this ceiling
Result: Better grounding in relevant evidence
In practice, better retrieval beats smarter models. This is why specialized search APIs like Exa exist—they're optimized for a specific retrieval task (LLM grounding) rather than general ranking.
Yes, Google AI Mode is excellent. Gemini 3 is a sophisticated model with Google's massive index behind it. For most straightforward questions, it's faster and more familiar than searching multiple sources.
No, Exa is generally superior. Not because Exa has a smarter model (it often doesn't), but because Exa's retrieval architecture is optimized for how LLMs actually need information.
This is the critical insight: Google's AI Mode gives you a smarter synthesis of weaker sources. Exa with a less sophisticated LLM gives you a less polished but better-grounded answer. In RAG applications, grounding usually matters more than polish.
The evidence is clear:
Gemini 3 with Google's index often retrieves high-authority pages that aren't semantically optimal
Even with superior intelligence, Gemini 3 struggles with queries where semantic relevance and mainstream authority diverge
Simpler LLMs with Exa frequently outperform on technical, niche, and complex reasoning tasks
The limiting factor for Gemini 3 isn't intelligence—it's the retrieval ceiling imposed by Google's index

The fundamental issue is that Google's AI Mode is trying to serve two masters: human users and LLMs. It can't optimize for both because they want fundamentally different things.
Fast answers
Trusted sources
Clear, synthesized information
Exploration and discovery
Semantic density
Full-text context
Evidence trails
Reasoning precision
Google optimizes for the first list. That's good business—billions of humans use Google. But it creates inevitable constraints for the second list.
Exa optimizes for the second list. It's a smaller market, but it's a more precise market.
Gemini 3's superior intelligence can't change the fact that Google's retrieval system was built for humans, not machines. And once the retrieval is constrained, intelligence becomes a secondary factor.
Here's the thing that matters for your strategy: This analysis doesn't diminish SEO. It expands the game board.
Human search is still massive. Billions of queries per day go to Google. People still click on high-ranking pages. Authority, trust signals, and ranking optimization still matter for human audiences. SEO remains a critical discipline.
But now there's another search channel growing in parallel:
LLM-powered search (Perplexity, Claude with web search, custom AI agents)
Retrieval-augmented generation pipelines
Internal knowledge systems using semantic search
AI-powered customer support and discovery tools
In this new channel, traditional SEO ranking signals don't work. Authority doesn't determine retrievability. Keyword optimization doesn't help. Backlink profiles are irrelevant.
Instead, what matters is:
Can the content be understood as meaning, not just keywords?
Can the content be extracted and used as evidence?
Does the content provide explicit, full-text context for reasoning?
Is the content the most relevant to the specific semantic query?
This isn't an either/or choice. Smart organizations now need both:
Ranking optimization
Intent-driven structure
Trust and authority signals
User engagement metrics
Semantic clarity and precision
Full-text evidence and context
Chunk-level accessibility
Semantic relevance independent of authority
The future of enterprise content strategy isn't abandoning SEO. It's building content that performs in both retrieval systems. That requires understanding both architectures—and most organizations don't.
The competitive advantage isn't picking sides. It's recognizing that:
SEO is foundational — Human search still drives the majority of traffic and revenue. You need to rank.
Generative search is emerging — But it's growing. And organizations that optimize only for Google are leaving themselves out of AI-powered discovery, agent-based search, and retrieval-augmented applications.
The best strategy addresses both — Content that ranks in Google AND gets retrieved by LLMs. Infrastructure that supports both authority-based and semantic-based ranking.
This is where agencies that understand both worlds have an advantage. You can't just be a traditional SEO agency anymore. But you also can't just chase AI trends and ignore the web's ranking foundations.
The organizations winning now are the ones building for both humans and machines. They're investing in:
Content architecture that serves dual purposes
Semantic optimization alongside traditional SEO
Discovery strategies that span Google, LLMs, and specialized search APIs
Measurement frameworks that track performance across both channels
That's the next generation of search strategy. Not replacing SEO—expanding it.
The future of content strategy isn't choosing between SEO and AI search—it's mastering both. We help organizations build content that ranks in Google AND gets retrieved by LLMs.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474.
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., & Wang, H. (2024). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
Sharma, C. (2025). Retrieval-augmented generation: A comprehensive survey of architectures, enhancements, and robustness frontiers. arXiv preprint arXiv:2506.00054.
Joren, H., Zhang, J., Ferng, C., & Taly, A. (2025). Sufficient context: A new lens on retrieval augmented generation systems. International Conference on Learning Representations (ICLR). Google Research.
Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., & Yih, W. (2020). Dense passage retrieval for open-domain question answering. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 6769-6781.
Page, L., Brin, S., Motwani, R., & Winograd, T. (1999). The PageRank citation ranking: Bringing order to the web. Stanford InfoLab Technical Report.
Google. (2024). A guide to Google Search ranking systems. Google Search Central Documentation.
Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023). RAGAS: Automated evaluation of retrieval augmented generation. arXiv preprint arXiv:2309.15217.
Chen, J., Lin, H., Han, X., & Sun, L. (2024). Benchmarking large language models in retrieval-augmented generation. Proceedings of the AAAI Conference on Artificial Intelligence, 38(16), 17754-17762.
IBM Research. (2024). What is retrieval-augmented generation (RAG)? IBM Research Blog.
Gupta, S., Ranjan, R., & Vaddadi, V. (2024). A comprehensive survey of retrieval-augmented generation (RAG): Evolution, current landscape and future directions. arXiv preprint arXiv:2410.12837.